
基于电子商务平台的大数据挖掘系统开发—推荐子系统
无需注册登录,支付后按照提示操作即可获取该资料.
基于电子商务平台的大数据挖掘系统开发—推荐子系统(论文20000字)
摘 要
近年来,随着淘宝,京东等电子商务平台的快速发展,让人们意识到了互联网以及大数据的重要性。为了增加用户的粘着性,给用户提供更好的服务,基于大数据的推荐系统应运而生。但是海量数据的存储、分析、挖掘对于每一个电子商务平台来说都是一个巨大的挑战。
本论文的工作重点主要有:大数据平台的搭建、海量数据的存储与运算、推荐系统的开发与设计。在Hadoop生态下,使用Lambda架构对大数据平台进行搭建,主要开发语言是 JAVA和Scala。海量日志的收集是通过网页埋点的形式向Flume发送日志,并由Flume收集至Kafka和HDFS实现。系统使用MapReduce和HIVE处理离线数据,Spark处理近线和实时数据。使用爬虫技术解决数据来源问题,收录了二十余万件京东商品。设计了一种通过比重控制随机值的设计思想,解决了订单和用户等数据来源。
推荐系统的算法使用了协同过滤算法,分为实时推荐和离线推荐两个部分,实时推荐是使用基于商品的协同过滤实现,离线推荐使用了基于用户的协同过滤实现。
关键词:电子商务平台;大数据;hadoop生态;协同过滤;推荐系统
Development of Large Data Mining System Based on
E-commerce Platform-Recommendation Subsystem
Abstract
In recent years, with the rapid development of e-commerce platforms such as taobao and jingdong, people have realized the importance of the Internet and big data. In order to increase the stickiness of users and provide them with better services, the recommendation system based on big data came into being.However, a large number of data storage, analysis and in-depth research on any e-commerce platform is a huge challenge and pressure that cannot be ignored.
This paper mainly focuses on the construction of big data platform, the storage and calculation of massive data, and the development and design of recommendation system. In the hadoop ecosystem, lambda architecture is used to build the big data platform, and the main development languages are JAVA and scala. The collection of massive logs is to send logs to flume in the form of web page embedded point, and to Kafka and HDFS by flume collection. The system USES MapReduce and HIVE to process offline data, and Spark to process near-line and real-time data. Using crawler technology, we found the final solution to the data source problem, and then concentrated more than 200,000 jd products. A design idea of controlling random value by specific gravity is designed to solve the problem of data sources such as orders and users. The algorithm of recommendation system adopts collaborative filtering algorithm.The realization of online recommendation mainly relies on collaborative filtering based on commodities, while cache recommendation mainly relies on collaborative filtering based on users.
Key words: e-commerce platform, big data, Hadoop ecology, collaborative filtering, recommendation system
目录
摘 要 I
Abstract II
第一章 引 言 1
1.1研究背景与意义 1
1.2推荐系统研究现状 2
1.3系统设计目标 2
1.4论文主要工作及结构安排 2
第二章 核心技术介绍 4
2.1系统架构介绍 4
2.1.1 分布式服务架构 4
2.1.2 大数据Lambda系统架构 4
2.2 Hadoop生态介绍 5
2.2.1 Hadoop介绍 5
2.2.2 HDFS介绍 6
2.2.3 MapReduce介绍 6
2.2.3 flume介绍 7
2.2.4 kafka介绍 7
2.2.5 Hive介绍 7
2.2.6 Spark介绍 8
2.2.7 ZooKeeper介绍 8
第三章 协同过滤算法 9
3.1协同过滤算法简介 9
3.2 协同过滤算法分类 9
3.2.1 以用户为基础(User-based)的协同过滤 9
3.2.2 以项目为基础(Item-based)的协同过滤 10
3.3 算法详解 10
第四章 系统分析 13
4.1 可行性分析 13
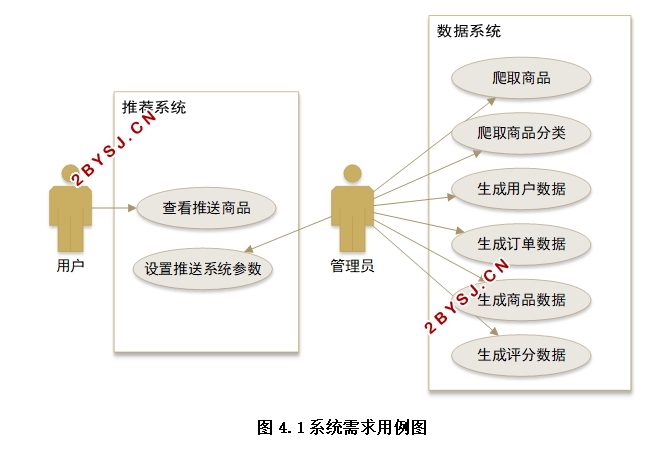
4.2 功能需求分析 13
4.3 业务流程分析 14
4.3.1 数据源业务流程分析 14
4.3.2 日志系统业务流程分析 15
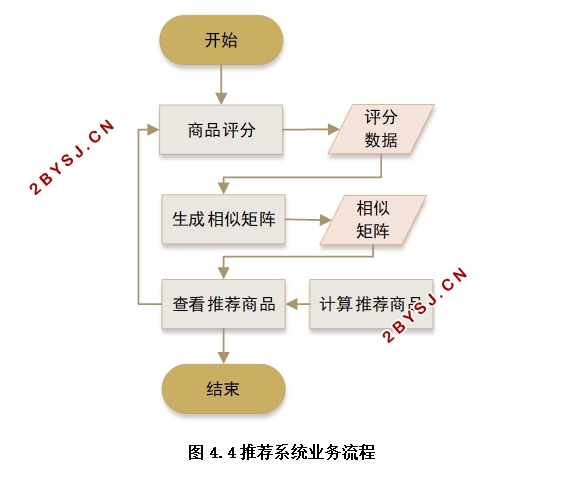
4.3.3 推荐系统业务流程分析 16
4.4 数据流程分析 16
第五章 系统设计 18
5.1 系统总体设计 18
5.1.1 服务交互设计 19
5.2.2 Hadoop平台架构设计 19
5.2.3 推荐系统架构设计 20
5.2 系统功能设计 21
5.3 系统类设计 23
5.3 数据库设计 29
5.3.1 概念模型设计 29
5.3.2 数据库表设计 30
第六章 系统实现 33
6.1 平台搭建 33
6.1.1 Hadoop基础平台搭建 34
6.1.2 其他服务搭建 37
6.1 日志系统 41
6.1.1 网页埋点 41
6.1.2 日志收集 41
6.1.3 数据清洗 42
6.1.4 数据处理 43
6.2 数据系统 44
6.3 爬虫系统 46
6.4 推荐系统 50
6.4.1 ALS算法参数 50
6.4.2 数据准备 50
6.4.3 模型训练与评估 51
6.4.4推荐系统实现 53
第七章 系统测试 56
7.1 推荐系统测试 56
7.2数据流测试 56
第八章 总 结 58
致 谢 59
参考文献 60