
网页搜索引擎的设计与实现(JSP+MySQL)(精品)☆
无需注册登录,支付后按照提示操作即可获取该资料.
摘 要:随着互联网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就象大海捞针一样,搜索引擎技术恰好解决了这一难题(它可以为用户提供信息检索服务)。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。本文首先详细介绍了搜索引擎的开发过程,着重介绍爬虫算法的分析,设计编码,以及在爬虫的开发过程中用到的主要技术,如lucene和Compass建立索引,使用htmlparse进行网页的处理与分析,在进行处理的时候用到的中文分词技术,以及使用多线程来提高爬虫的效率,还有在提示部分使用jdbc数据库连接池来提高提示的效率,如何进行分页等等。通过本论文的介绍,将会对搜索引擎的架构有一定的认识。同时在设计此系统的时候也借鉴了同类型系统的许多优点,例如google的suggest,当然此系统还不具备一个成熟的商业系统的价值,在搜索引擎的世界中google和百度占据着重要的地位。希望通过此系统能够对研究搜索引擎的爱好者提供帮助。
关键词:搜索引擎;爬虫;多线程;中文分词;索引
毕业设计(论文)外文摘要
Web Search Engine Design and Implementation
Abstract: With the rapid development of Internet and increasing of web information, the users are difficult to get their desired information. The search engine technology is just one technology that can solve the problem (it can provide users with information retrieval services). At present, the search engine technology is becoming the computer industry and the academic competition research and development of the object. At this article ,firstly introduce the details the development of search engines, then focused on reptiles algorithm analysis, design ,codes, as well as reptiles of the development process of the main techniques used, such as indexing lucene and Compass, the use of web htmlparse processing and analysis, when used in dealing with the Chinese word segmentation technology, and the use of multi-threaded to improve the efficiency of reptiles, there are some tips to use in the jdbc database connection pool to improve, suggesting that the efficiency of how the page and so on. Through the introduction of this paper will be the framework of the search engines know something about it. At the same time in the design of this system when the same type of system from the many advantages, such as google's suggest, of course, this system does not have a maturity value of the business systems. Baidu and google occupy important position in the world of search engine. I hope that the researcher of search engine will get useful information through this system.
Keywords: Search engine; reptiles; multi-threaded; Chinese word segmentation; indexing
系统功能需求分析
网页搜索引擎的系统需求如下:
能够使用爬虫爬到网上的大量数据,且不重复。
能够对输入的关键字进行提示。
能够通过输入的条件查询到结果。
系统介绍
系统主要有三个体系子系统构成:
1 爬虫算法的设计
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,如图1(a)流程图所示。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,如图1(b)所示。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索
2 前台页面的设计
前台页面对于关键字的提示,只需在搜索框中键入内容,相关搜索字词的建议便会随之自动显示。使用的是googleSuggest,它使用连接池当确定关键词的时候请求系统,查询文件系统,使用连接池,把暂时不使用的链接放入连接池,到需要使用的时候,从连接池中取出链接使用 ,可以节省初始化的时间,将返回的 结果分页显示,分页使用的分页框架pagerlib,这个框架可以设计出,像google,baidu,yahoo以及其他一些大型网站的分页功能。
3 数据库表以及文件系统的设计
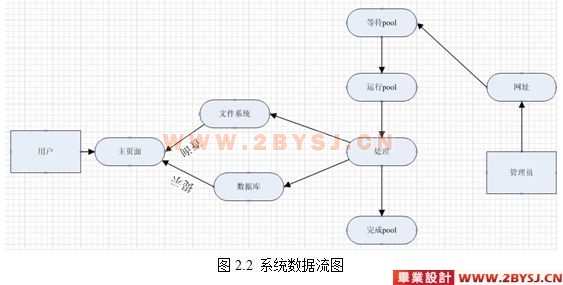
此系统由数据库和文件系统俩部分组成,数据库主要用于对提示的查询,文件系统主要应用在数据库对关键字的查询,使用索引建立的文件系统,搜索效率是远高于数据看的。
数据库设计
系统总体结构功能模块设计后,就要对数据库进行设计。数据库模式定义了数据库的结构、表、关系和业务规则。数据库模式是一种设计,数据库和应用正是建立在此基础上。
本系统属于除此开发,无历史遗留问题,此数据库设计包括文件系系统和数据库系统俩大部分,文件系统主要为查询提供结果,数据库主要为提示提供结果。
数据库和文件系统设计是一样的。
系统架构分层介绍
本系统整体的架构采用MVC体系结构,使用MVC体系架构,应用程序被分成三个核心部件:模型(Model)、视图(View)、控制器(Controller),它们各自处理自己的任务。
爬虫模块详细设计
该模块的主要任务是运行爬虫将爬到的内容存储到数据库和文件系统之中。首先要初始化链接的数量,其次要初始化线程的数量,线程的数量必须少于链接的数量,由于线程是死循环运行,当链表中的链接没有的时候,线程就会退出去,该爬虫算法设计的时候使用了三个链表,等待链表,运行链表,已完成链表,刚开始先将链接初始化到等待链表,然后线程运行从等待链表中取出链接来进行处理,如没有则退出,现将该链接加入到运行链表,处理的时候先通过链接打开该网址,然后一次获取该网址的titile,meta中的keywords ,description,处理关键字的时候应注意,由于每个网址的关键字都多余一个所以处理的时候,先要整体获取,然后再用中文或英文逗号予以分割,如果是首次处理该网络内部的链接的话,就要设置它的权值为1,如果不是,那么根据取出来的权值加1,一直加到3以后就不处理了,因为权值越高,处理的信息量也就越大,而这些信息的重要程度就越低,处理的话会降低程序的性能。在处理链接的时候要分清楚,是内链接还是外连接,还是其他的链接,对于其他的链接本程序直接不让它加入等待链表,对于内连接要看它的权值而定,是否加入等待链表,执行完成后再将该链接加入到完成链表。继续从等待链表中取链接执行。
系统Windows2000/xp/2003/NT/LINUX 数据库MySQL5.0 运行环境 希捷硬盘 Tomcat6.0 +IE6.0以上/Firofox2.0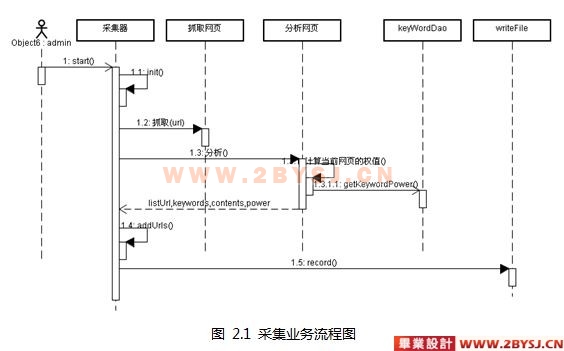



目 录
1 绪论 1
1.1.搜索引擎的历史 1
1.2.搜索引擎的分类 2
1.3.搜索引擎的基本原理 3
1.4.系统介绍 4
1.4.1 爬虫算法的设计 4
1.4.2 前台页面的设计 4
1.4.3 数据库表以及文件系统的设计 4
2 系统需求分析 5
2.1 系统功能需求分析 5
2.2 业务流程分析 5
2.3 数据流分析 6
2.4 数据字典 6
3 系统设计 8
3.1 系统总体结构设计 8
3.2 数据库设计 8
3.2.1 E-R图 8
3.2.2 数据库主键增长策略 10
3.2.3 关系模式 11
3.2.4 数据表 11
3.3 系统开发工具和框架 11
3.3.1 hibernate框架简介 11
3.3.2struts1.2框架简介 12
3.3.3 spring 框架介绍 13
3.3.4 lucene 介绍 14
3.3.5 其他介绍 14
(优秀毕业设计:www.2bysj.cn)
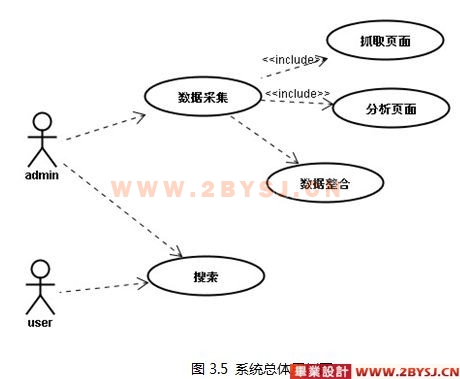
3.4系统总体用例图 15
4 系统整体架构设计 18
4.1 系统架构分层介绍 18
5 详细设计 21
5.1爬虫模块详细设计 21
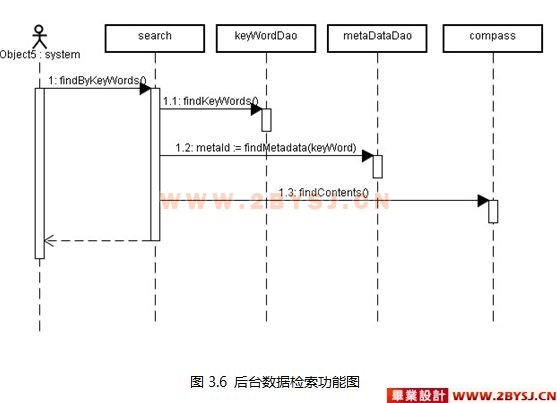
5.2 搜索模块详细设计 23
5.3提示模块详细设计 25
6 遇到的问题与解决方案 27
6.1 查询乱码问题 27
6.2 处理页面链接问题 27
6.3 线程与连接的数量问题 27
6.4效率问题 27
6.5 servlet提示查询问题 27
6.6处理一个页面的时间问题 28
6.7 线程处理页面无限处理的问题 28
6.8 爬虫运行时间过长 28
6.9 重复添加的情况 28
6.10重复结果问题 28
7 用户使用手册 29
7.1 功能介绍 29
8系统配置与操作指南 30
8.1服务器端系统配置 30
8.2 系统操作指南 30
9系统评价 33
9.1 系统特色 33
9.2 系统存在的不足 33
9.3 心得体会 33
结 论 35
致 谢 36
参 考 文 献 37
参 考 文 献
[1]常晓燕.基于JAVA的新闻搜索引擎的设计与实现[D].西南理工大学硕士研究生论文.2004.
[2]吴东华.Web信息获取技术研究[D].南京理工大学硕士研究生论文.2004.
[3]何世林.基于JAVA技术的搜索引擎研究与实现[D].西南交通大学硕士论文.2006.
[4]何玉箐.基于XML\JAVA的元搜索引擎的研究[D].广东工业大学硕士论文.2004.
[5]黄国景.元搜索引擎个性化搜索的研究与设计[D].苏州大学硕士论文.2005.
[6]侯震宇.主题型搜索引擎的研究与实现[M].中国科学院研究生院.2003.
[7]李晓明,闫宏飞,王继民.搜索引擎-原理技术与系统[M].科学出版社.2004.
[8]谭淑英,刘丽华.Web Robot技术及其JAVA实现[J].中南工业大学学报.32(6):325-327.2001.
[9]谭淑英,刘丽华.网络机器人访问网站网页的安全限制[J].南华大学学报. 15(1):42-44.2001.
[10]Jeff Heaton.网络机器人JAVA编程指南[M].电子工业出版社.2002.
[11]宋聚平,王永成,滕伟,许欢庆.搜索引擎中Robot搜索算法的优化[J].情报学报.21(2):130-133.2002.
[12]㑇海山,吴庸,吴月珠.中文搜索引擎中的中文信息处理技术[M].计算机应用研究.2000.